Оптимизация производительности операций вставки и чтения в S3
В этом разделе основное внимание уделяется оптимизации производительности при чтении и вставке данных из S3 с использованием табличной функции s3.
Описанный в этом руководстве подход можно применить и к другим реализациям объектного хранилища с собственными табличными функциями, таким, как GCS и Azure Blob Storage.
Прежде чем настраивать число потоков и размеры блоков для улучшения производительности вставки, мы рекомендуем сначала разобраться в механизме вставки данных в S3. Если вы уже знакомы с этим механизмом или хотите получить только краткие рекомендации, переходите сразу к нашему примеру ниже.
Механизм вставки (одиночный узел)
На производительность и потребление ресурсов механизма вставки данных ClickHouse на одном узле, помимо конфигурации оборудования, влияют два основных фактора: размер блока вставки и параллелизм вставки.
Размер блока вставки
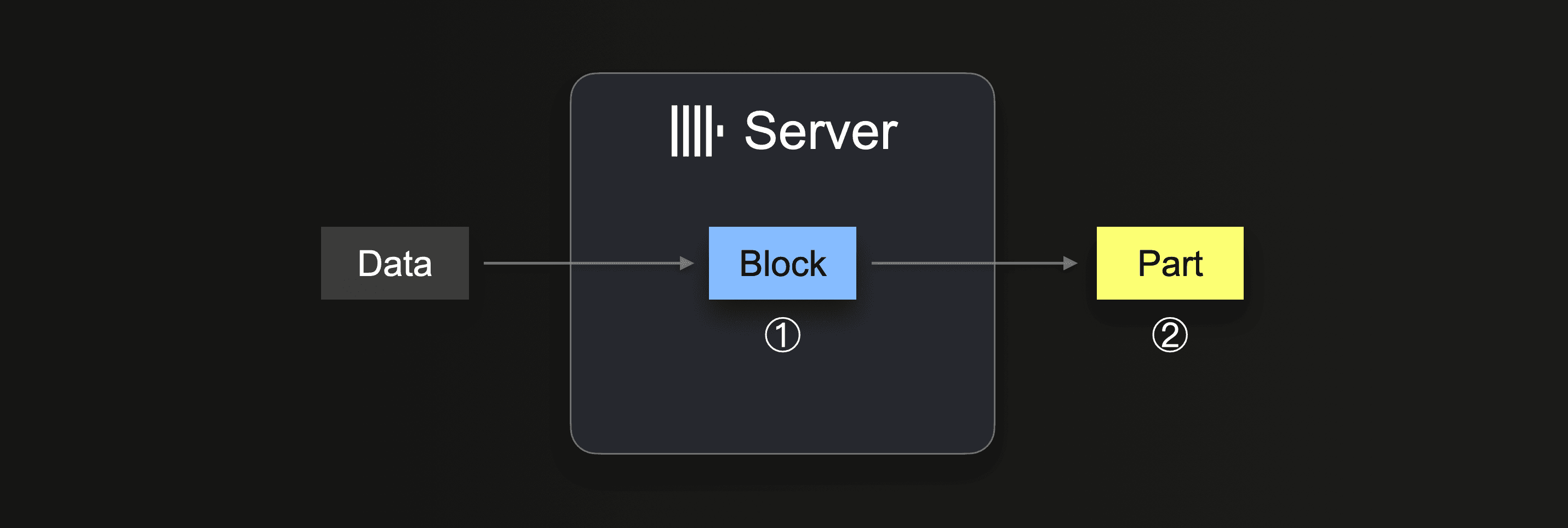
При выполнении INSERT INTO SELECT ClickHouse получает некоторый объём данных и ① формирует (как минимум) один блок вставки в памяти (для каждого ключа партиционирования) из полученных данных. Данные блока сортируются, и применяются оптимизации, специфичные для табличного движка. Затем данные сжимаются и ② записываются в хранилище базы данных в виде новой части данных.
Размер блока вставки влияет как на использование дискового ввода-вывода, так и на использование памяти сервером ClickHouse. Более крупные блоки вставки используют больше памяти, но формируют более крупные и менее многочисленные исходные части. Чем меньше частей нужно создать ClickHouse при загрузке большого объёма данных, тем меньше требуется дискового ввода-вывода и автоматических фоновых слияний.
При использовании запроса INSERT INTO SELECT в сочетании с интеграционным табличным движком или табличной функцией данные забираются сервером ClickHouse:
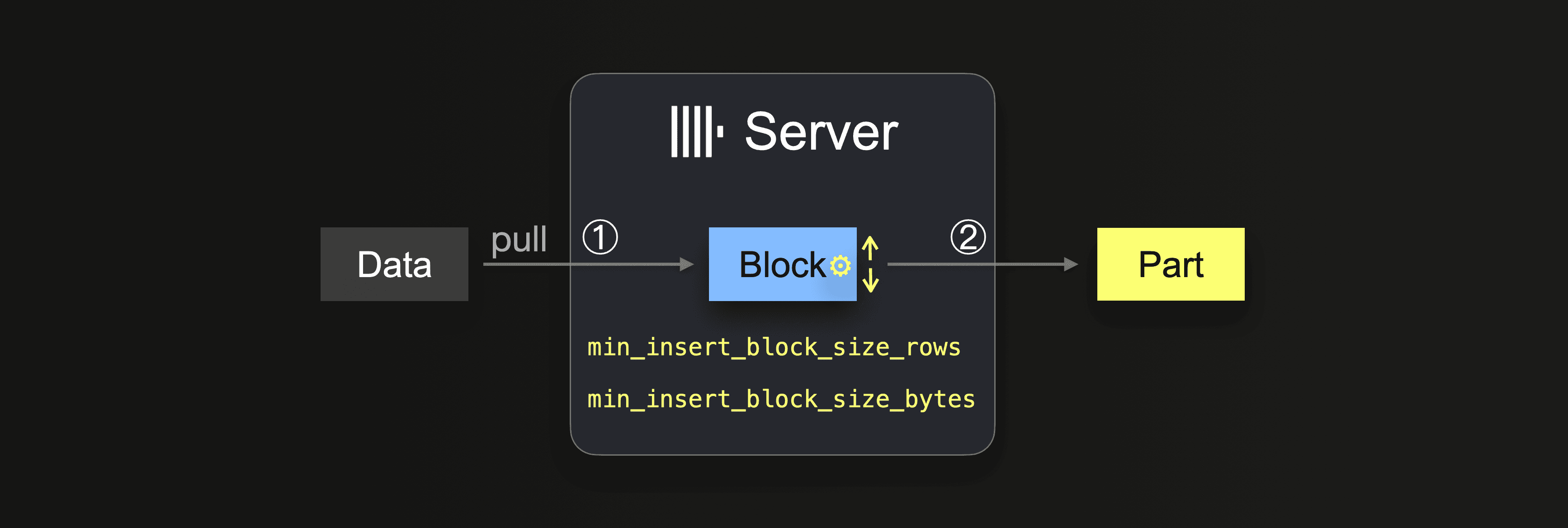
Пока данные не будут полностью загружены, сервер выполняет цикл:
На шаге ① размер блока зависит от размера блока вставки, который можно контролировать двумя настройками:
min_insert_block_size_rows(по умолчанию:1048545миллионов строк)min_insert_block_size_bytes(по умолчанию:256 MiB)
Когда в блоке вставки накапливается либо указанное количество строк, либо достигается настроенный объём данных (в зависимости от того, что произойдёт раньше), блок записывается в новую часть. Цикл вставки продолжается с шага ①.
Обратите внимание, что значение min_insert_block_size_bytes обозначает несжатый размер блока в памяти (а не сжатый размер части на диске). Также обратите внимание, что созданные блоки и части редко в точности содержат настроенное количество строк или байт, поскольку ClickHouse передаёт и обрабатывает данные в потоковом режиме, по строкам и блокам. Поэтому эти настройки задают минимальные пороговые значения.
Учитывайте слияния
Чем меньше настроенный размер блока вставки, тем больше исходных частей создаётся при большой загрузке данных и тем больше фоновых слияний частей выполняется параллельно с ингестией данных. Это может вызвать конкуренцию за ресурсы (CPU и память) и потребовать дополнительного времени (для достижения здорового (3000) числа частей) после завершения ингестии.
Производительность запросов ClickHouse будет ухудшаться, если количество частей превысит рекомендуемые пределы.
ClickHouse будет постоянно сливать части в более крупные части, пока они не достигнут сжатого размера около 150 GiB. Эта диаграмма показывает, как сервер ClickHouse выполняет слияния частей:
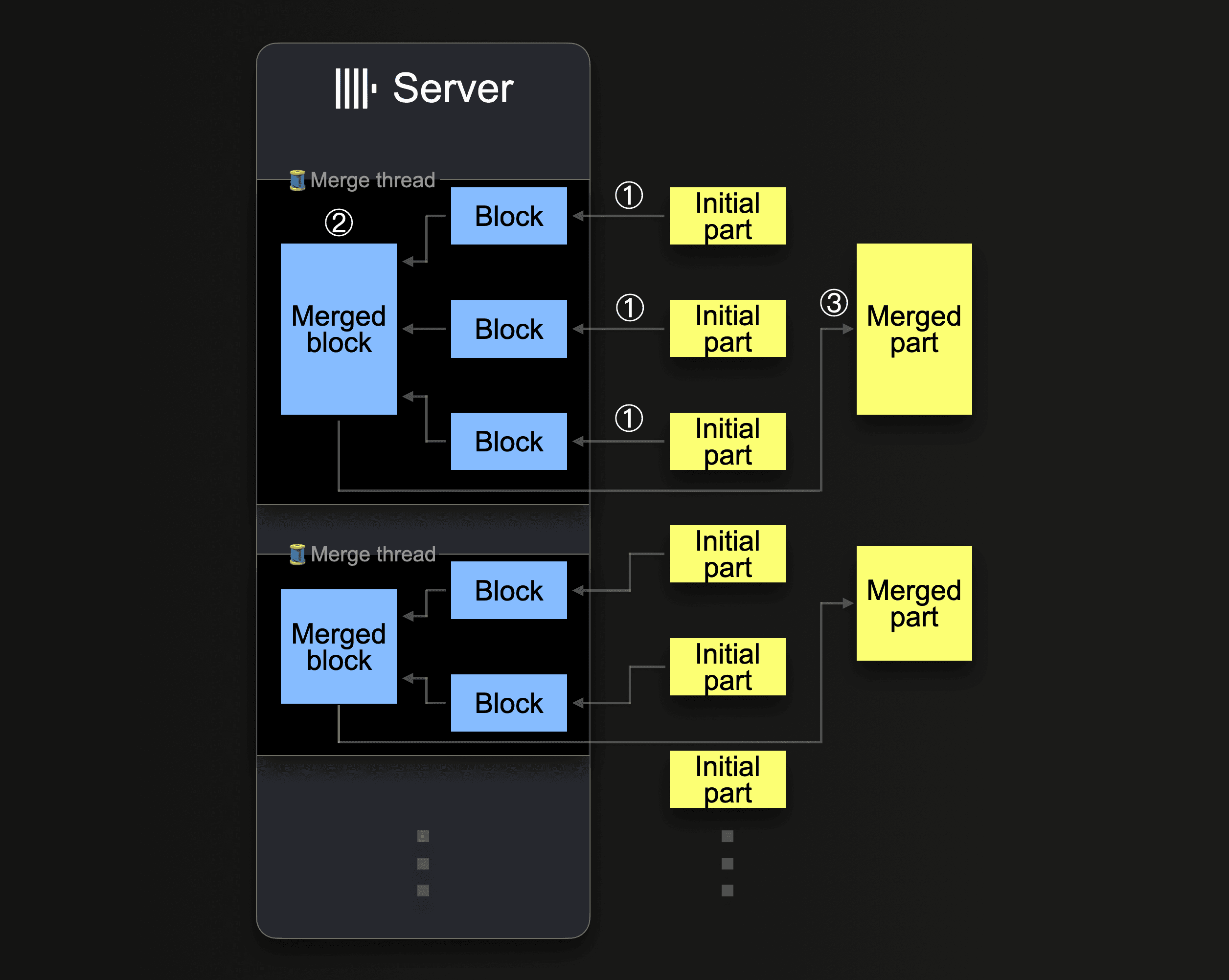
Один сервер ClickHouse использует несколько фоновых потоков слияний для выполнения параллельных слияний частей. Каждый поток выполняет цикл:
Обратите внимание, что увеличение количества ядер CPU и объёма RAM повышает пропускную способность фоновых слияний.
Части, которые были объединены в более крупные части, помечаются как неактивные и в конечном итоге удаляются через настраиваемое время (в минутах). Со временем это создаёт дерево слитых частей (отсюда и название таблицы MergeTree).
Параллелизм вставки
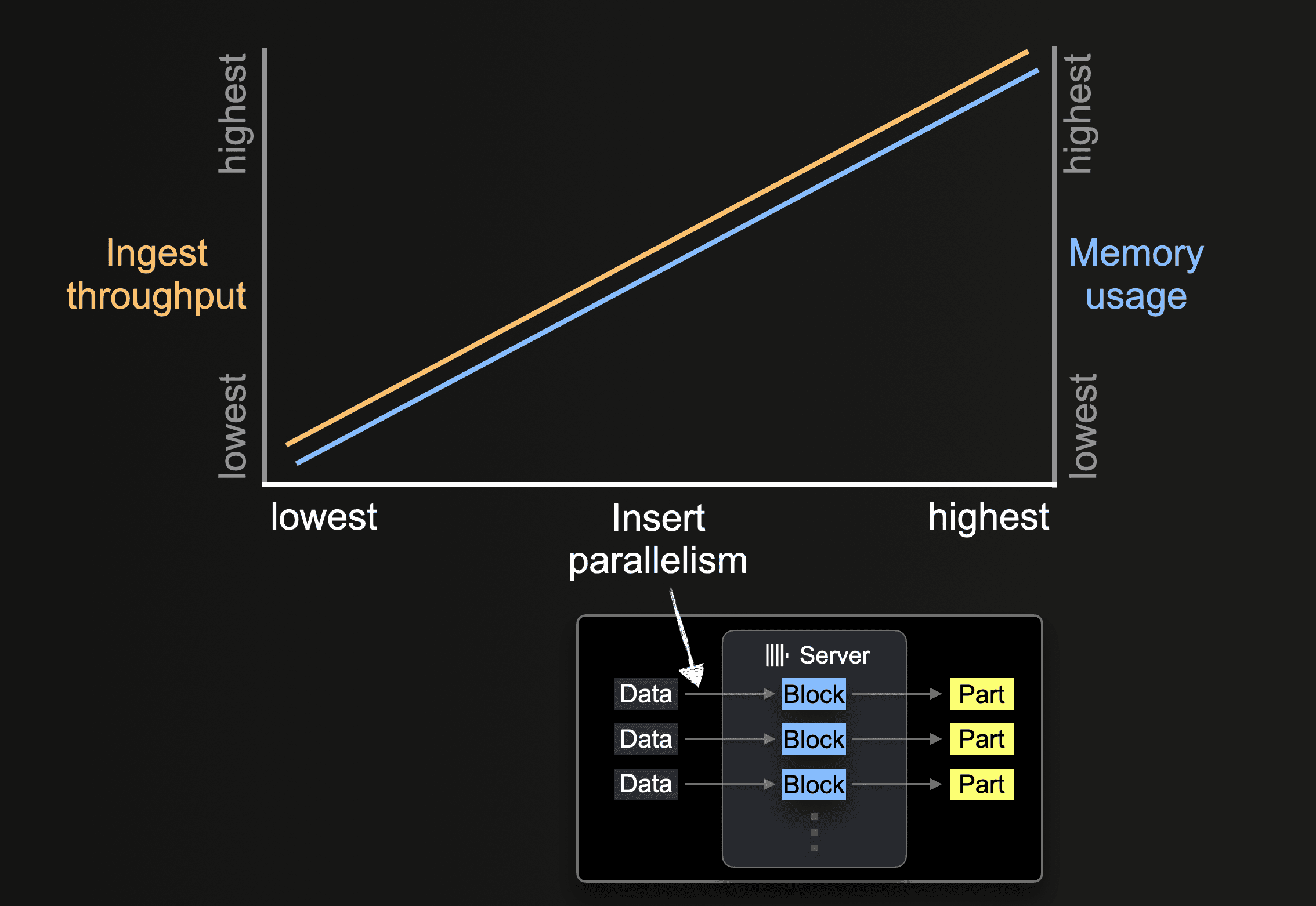
Сервер ClickHouse может обрабатывать и вставлять данные параллельно. Уровень параллелизма вставки влияет на пропускную способность приёма данных и использование памяти сервера ClickHouse. Загрузка и обработка данных параллельно требует больше оперативной памяти, но увеличивает пропускную способность приёма данных за счёт более быстрой обработки.
Табличные функции, такие как s3, позволяют указывать наборы имён файлов для загрузки с помощью glob-шаблонов. Когда glob-шаблон соответствует нескольким существующим файлам, ClickHouse может распараллелить чтение между этими файлами и внутри них, а также вставлять данные параллельно в таблицу, используя параллельно работающие потоки вставки (для каждого сервера):
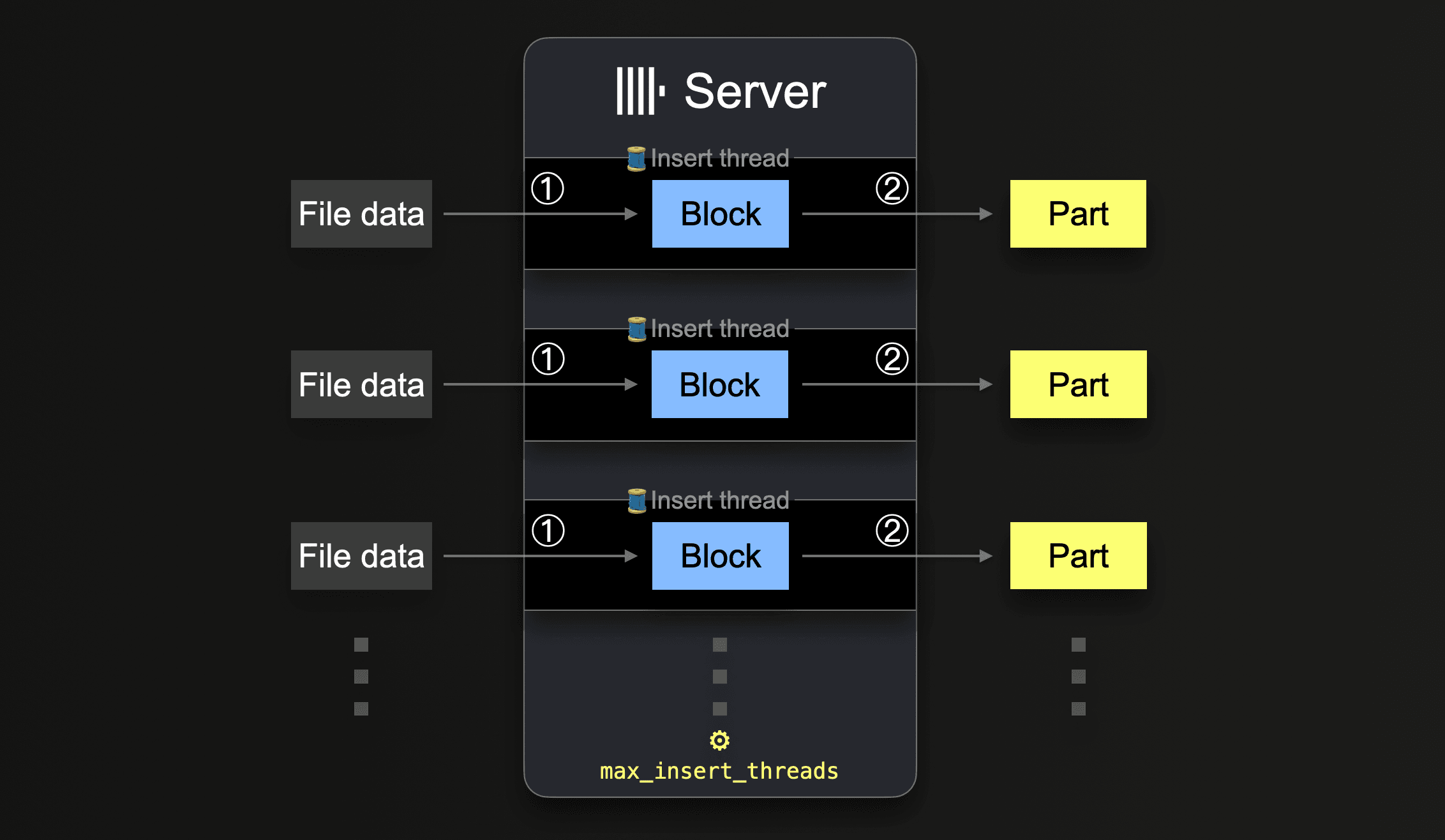
Пока не будут обработаны все данные из всех файлов, каждый поток вставки выполняет цикл:
Количество таких параллельных потоков вставки можно настроить с помощью параметра max_insert_threads. Значение по умолчанию — 1 для версии ClickHouse с открытым исходным кодом и 4 для ClickHouse Cloud.
При большом количестве файлов параллельная обработка несколькими потоками вставки работает эффективно. Она способна полностью задействовать как доступные ядра CPU, так и пропускную способность сети (для параллельной загрузки файлов). В сценариях, когда в таблицу загружается всего несколько крупных файлов, ClickHouse автоматически устанавливает высокий уровень параллелизма обработки данных и оптимизирует использование сетевой пропускной способности, создавая дополнительные потоки чтения на каждый поток вставки для параллельного чтения (загрузки) различных диапазонов внутри больших файлов.
Для функции и таблицы s3 параллельная загрузка отдельного файла определяется значениями max_download_threads и max_download_buffer_size. Файлы будут загружаться параллельно только в том случае, если их размер больше, чем 2 * max_download_buffer_size. По умолчанию значение max_download_buffer_size установлено в 10MiB. В некоторых случаях вы можете безопасно увеличить размер этого буфера до 50 MB (max_download_buffer_size=52428800), чтобы гарантировать, что каждый файл загружается одним потоком. Это может сократить время, которое каждый поток тратит на обращения к S3, и таким образом уменьшить время ожидания S3. Кроме того, для файлов, слишком маленьких для параллельного чтения, для увеличения пропускной способности ClickHouse автоматически предзагружает данные, предварительно читая такие файлы асинхронно.
Измерение производительности
Оптимизация производительности запросов с использованием табличных функций S3 необходима как при выполнении запросов к данным «на месте», то есть при ad‑hoc‑запросах, когда используются только вычислительные ресурсы ClickHouse, а данные остаются в S3 в исходном формате, так и при вставке данных из S3 в таблицу ClickHouse на движке MergeTree. Если не указано иное, следующие рекомендации применимы к обоим сценариям.
Влияние размеров аппаратной конфигурации
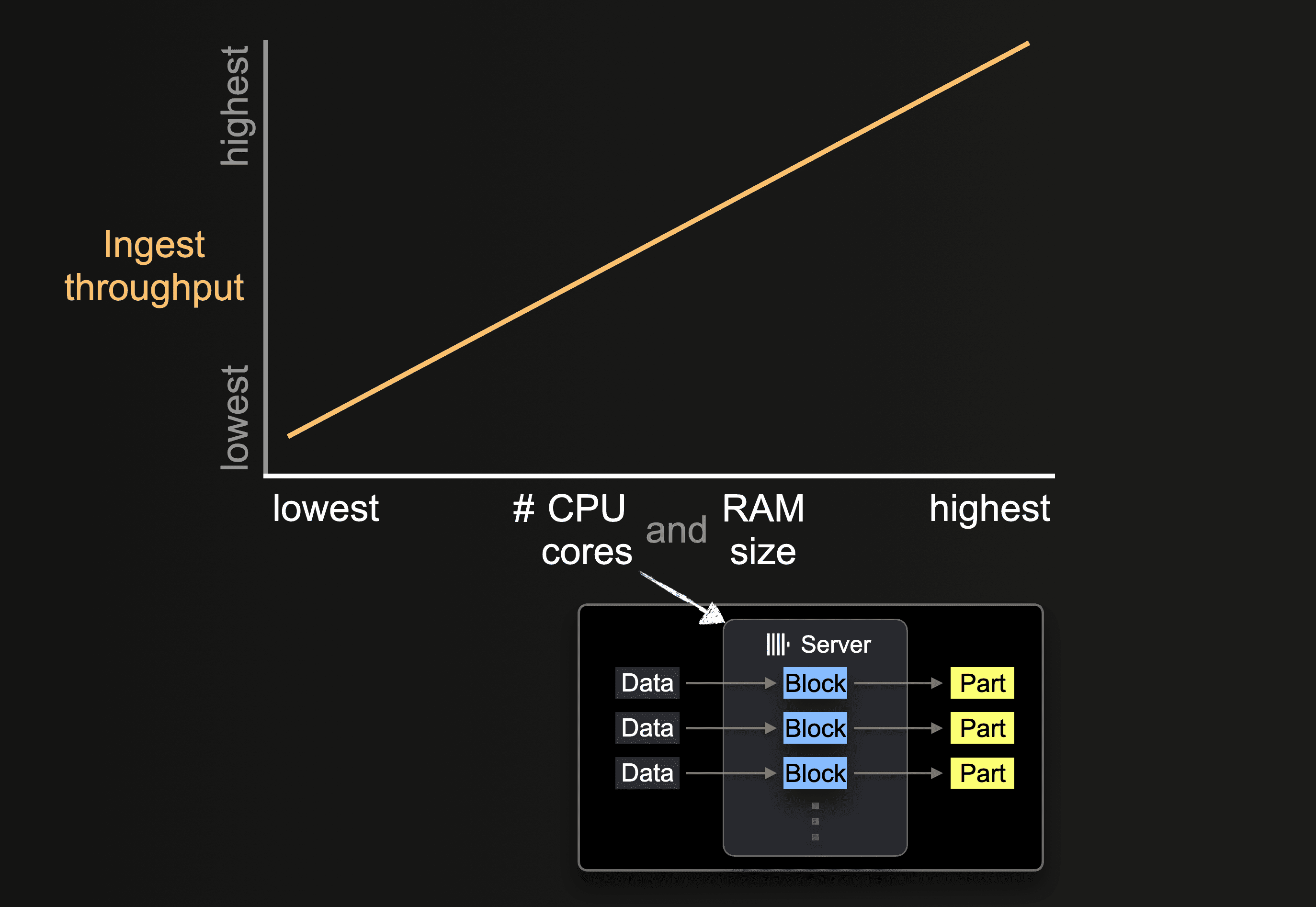
Количество доступных ядер CPU и объём оперативной памяти влияет на:
- поддерживаемый начальный размер частей
- возможный уровень параллелизма вставки
- пропускную способность фоновых слияний частей
и, следовательно, общую пропускную способность приёма данных.
Локальность региона
Убедитесь, что ваши бакеты находятся в том же регионе, что и экземпляры ClickHouse. Эта несложная оптимизация может значительно повысить производительность (пропускную способность), особенно если вы разворачиваете экземпляры ClickHouse в инфраструктуре AWS.
Форматы
ClickHouse может читать файлы, хранящиеся в бакетах S3, в поддерживаемых форматах с помощью функции s3 и движка S3. При чтении «сырых» файлов некоторые из этих форматов имеют определённые преимущества:
- Форматы с закодированными именами столбцов, такие как Native, Parquet, CSVWithNames и TabSeparatedWithNames, упрощают написание запросов, поскольку пользователю не нужно указывать имя столбца в функции
s3. Имена столбцов позволяют однозначно определить эту информацию. - Форматы отличаются по производительности чтения и записи. Native и Parquet являются наиболее оптимальными форматами для производительности чтения, поскольку они уже колонко-ориентированы и более компактны. Формат Native дополнительно выигрывает за счёт согласованности с тем, как ClickHouse хранит данные в памяти, тем самым снижая накладные расходы на обработку при потоковой загрузке данных в ClickHouse.
- Размер блока часто влияет на задержку чтения больших файлов. Это особенно заметно, если вы выполняете только выборочное чтение данных, например, возвращая первые N строк. В случае таких форматов, как CSV и TSV, файлы должны быть разобраны, чтобы вернуть набор строк. Форматы, такие как Native и Parquet, позволяют существенно ускорить выборочное чтение.
- Каждый формат сжатия имеет свои преимущества и недостатки, обычно балансируя уровень сжатия и скорость, смещая приоритет в сторону производительности сжатия или распаковки. При сжатии «сырых» файлов, таких как CSV или TSV, lz4 обеспечивает самую быструю распаковку, жертвуя степенью сжатия. Gzip, как правило, сжимает лучше, но ценой немного более медленного чтения. Xz идёт ещё дальше, обычно обеспечивая наилучшее сжатие при самой медленной скорости сжатия и распаковки. При экспорте Gz и lz4 обеспечивают сопоставимую скорость сжатия. Соотнесите это со скоростью вашего сетевого подключения. Любой выигрыш от более быстрой распаковки или сжатия легко будет нивелирован медленным подключением к вашим бакетам S3.
- Для форматов, таких как Native или Parquet, сжатие обычно не оправдывает накладные расходы. Любая экономия места, скорее всего, будет минимальной, поскольку эти форматы по своей сути компактны. Время, затраченное на сжатие и распаковку, редко компенсирует время сетевой передачи, особенно учитывая, что S3 глобально доступен с высокой пропускной способностью сети.
Пример набора данных
Чтобы продемонстрировать дальнейший потенциал оптимизации, в качестве примера мы будем использовать публикации из набора данных Stack Overflow, оптимизируя как производительность запросов, так и скорость вставки этих данных.
Этот набор данных состоит из 189 файлов Parquet, по одному на каждый месяц с июля 2008 по март 2024 года.
Обратите внимание, что мы используем Parquet для повышения производительности, в соответствии с нашими рекомендациями выше, выполняя все запросы на кластере ClickHouse, размещённом в том же регионе, что и бакет. Этот кластер состоит из 3 узлов, каждый с 32GiB оперативной памяти и 8 vCPU.
Без какой-либо дополнительной настройки мы демонстрируем производительность вставки этого набора данных в движок таблиц MergeTree, а также выполнения запроса для определения пользователей, задающих больше всего вопросов. Оба этих запроса намеренно требуют полного сканирования данных.
В нашем примере мы возвращаем только несколько строк. Если требуется измерить производительность запросов SELECT, в которых на клиент возвращаются большие объемы данных, используйте либо формат Null для запросов, либо направляйте результаты в движок Null. Это позволит избежать перегрузки клиента данными и сети трафиком.
При чтении результатов запросов начальный запрос может казаться более медленным, чем повторный запуск того же запроса. Это можно объяснить как собственным кэшированием S3, так и ClickHouse Schema Inference Cache. Этот кэш сохраняет выведенную схему для файлов, что позволяет пропустить этап вывода схемы при последующих обращениях и, таким образом, сократить время выполнения запроса.
Использование потоков для чтения
Производительность чтения из S3 масштабируется линейно с количеством ядер при условии, что вас не ограничивает пропускная способность сети или локальный ввод-вывод. Увеличение числа потоков также приводит к дополнительным затратам по памяти, о которых пользователям следует знать. Следующие параметры можно изменить для потенциального улучшения пропускной способности чтения:
- Обычно значения по умолчанию
max_threadsдостаточно, т.е. оно равно количеству ядер. Если объем памяти, используемой для запроса, высок и его необходимо уменьшить, илиLIMITна результаты невелик, это значение можно снизить. Пользователи с большим объемом памяти могут поэкспериментировать с увеличением этого значения для потенциально более высокой пропускной способности чтения из S3. Как правило, это полезно только на машинах с меньшим количеством ядер, т.е. < 10. Выгода от дальнейшего распараллеливания обычно снижается, так как другие ресурсы начинают выступать в роли узкого места, например сеть и CPU. - Версии ClickHouse до 22.3.1 распараллеливали чтение только по нескольким файлам при использовании функции
s3или движка таблицS3. Это требовало от пользователя обеспечить, чтобы файлы были разбиты на части в S3 и читались с использованием glob‑шаблона для достижения оптимальной производительности чтения. В более поздних версиях загрузка распараллеливается уже внутри одного файла. - В сценариях с небольшим количеством потоков пользователи могут получить выгоду от установки
remote_filesystem_read_methodв значение «read», чтобы включить синхронное чтение файлов из S3. - Для функции и таблицы s3 параллельная загрузка отдельного файла определяется значениями
max_download_threadsиmax_download_buffer_size. При этомmax_download_threadsуправляет количеством используемых потоков, а файлы будут загружаться параллельно только в том случае, если их размер больше чем 2 *max_download_buffer_size. По умолчанию значениеmax_download_buffer_sizeустановлено в 10MiB. В некоторых случаях вы можете безопасно увеличить этот размер буфера до 50 MB (max_download_buffer_size=52428800), чтобы гарантировать, что небольшие файлы загружаются только одним потоком. Это может сократить время, которое каждый поток тратит на выполнение вызовов S3, а значит, также уменьшить время ожидания S3. См. эту запись в блоге в качестве примера.
Перед внесением любых изменений для повышения производительности убедитесь, что вы корректно проводите измерения. Поскольку вызовы S3 API чувствительны к задержкам и могут влиять на время выполнения на стороне клиента, используйте журнал запросов для метрик производительности, т.е. system.query_log.
Рассмотрим наш предыдущий запрос: удвоение max_threads до 16 (по умолчанию max_threads равно количеству ядер на узле) улучшает производительность чтения примерно в 2 раза за счет большего потребления памяти. Дальнейшее увеличение max_threads дает убывающий эффект, как показано.
Настройка потоков и размера блоков для вставок
Чтобы достичь максимальной производительности ингестии, необходимо выбрать (1) размер блока вставки и (2) соответствующий уровень параллелизма вставки на основе (3) количества доступных ядер CPU и объёма доступной RAM. Вкратце:
- Чем больше мы задаём размер блока вставки, тем меньше частей ClickHouse должен создать и тем меньше требуется дисковых операций ввода-вывода и фоновых слияний.
- Чем выше мы задаём число параллельных потоков вставки, тем быстрее будут обрабатываться данные.
Между этими двумя факторами производительности существует компромисс (а также компромисс с фоновым слиянием частей). Объём доступной оперативной памяти серверов ClickHouse ограничен. Более крупные блоки используют больше оперативной памяти, что ограничивает количество потоков параллельной вставки, которые мы можем задействовать. И наоборот, большее число потоков параллельной вставки требует больше оперативной памяти, поскольку число потоков вставки определяет количество блоков вставки, создаваемых в памяти одновременно. Это ограничивает возможный размер блоков вставки. Кроме того, может возникать конкуренция за ресурсы между потоками вставки и фоновыми потоками слияния. Большое число настроенных потоков вставки (1) создаёт больше частей, которые необходимо сливать, и (2) отбирает ядра CPU и объём памяти у фоновых потоков слияния.
Для подробного описания того, как поведение этих параметров влияет на производительность и потребление ресурсов, мы рекомендуем прочитать эту публикацию в блоге. Как описано в этой публикации, настройка может включать аккуратный баланс между двумя параметрами. Подобное исчерпывающее тестирование часто непрактично, поэтому, подводя итог, мы рекомендуем следующее:
С помощью этой формулы вы можете установить min_insert_block_size_rows в 0 (чтобы отключить порог по количеству строк), при этом задать max_insert_threads выбранным значением, а min_insert_block_size_bytes — вычисленным по приведённой выше формуле результатом.
Применим эту формулу к нашему предыдущему примеру со Stack Overflow.
max_insert_threads=4(8 ядер на узел)peak_memory_usage_in_bytes— 32 GiB (100% ресурсов узла) или34359738368байт.min_insert_block_size_bytes=34359738368/(3*4) = 2863311530
Как видно, настройка этих параметров повысила скорость вставки более чем на 33%. Предлагаем читателю попытаться ещё больше повысить производительность отдельного узла.
Масштабирование по ресурсам и узлам
Масштабирование по ресурсам и узлам применяется как к запросам на чтение, так и к запросам на вставку.
Вертикальное масштабирование
Все предыдущие настройки и запросы использовали только один узел в нашем кластере ClickHouse Cloud. Пользователям также часто доступно несколько узлов ClickHouse. Мы рекомендуем сначала масштабироваться по вертикали, линейно увеличивая пропускную способность S3 с ростом числа ядер. Если мы повторим наши предыдущие запросы на вставку и чтение на более крупном узле ClickHouse Cloud с вдвое большим объёмом ресурсов (64GiB, 16 vCPU) и соответствующими настройками, оба запроса будут выполняться примерно в два раза быстрее.
Отдельные узлы также могут становиться узким местом из‑за ограничений сети и запросов S3 GET, что мешает линейно наращивать производительность при вертикальном масштабировании.
Горизонтальное масштабирование
В конечном итоге горизонтальное масштабирование часто становится необходимым из‑за ограничений доступности оборудования и требований к экономической эффективности. В ClickHouse Cloud производственные кластеры имеют как минимум 3 узла. Пользователи также могут захотеть задействовать все узлы для операции вставки.
Использование кластера для чтения из S3 требует применения функции s3Cluster, как описано в разделе Utilizing Clusters. Это позволяет распределить чтение по узлам.
Сервер, который изначально получает запрос на вставку, сначала разворачивает glob‑шаблон, а затем динамически распределяет обработку каждого соответствующего файла между собой и другими серверами.
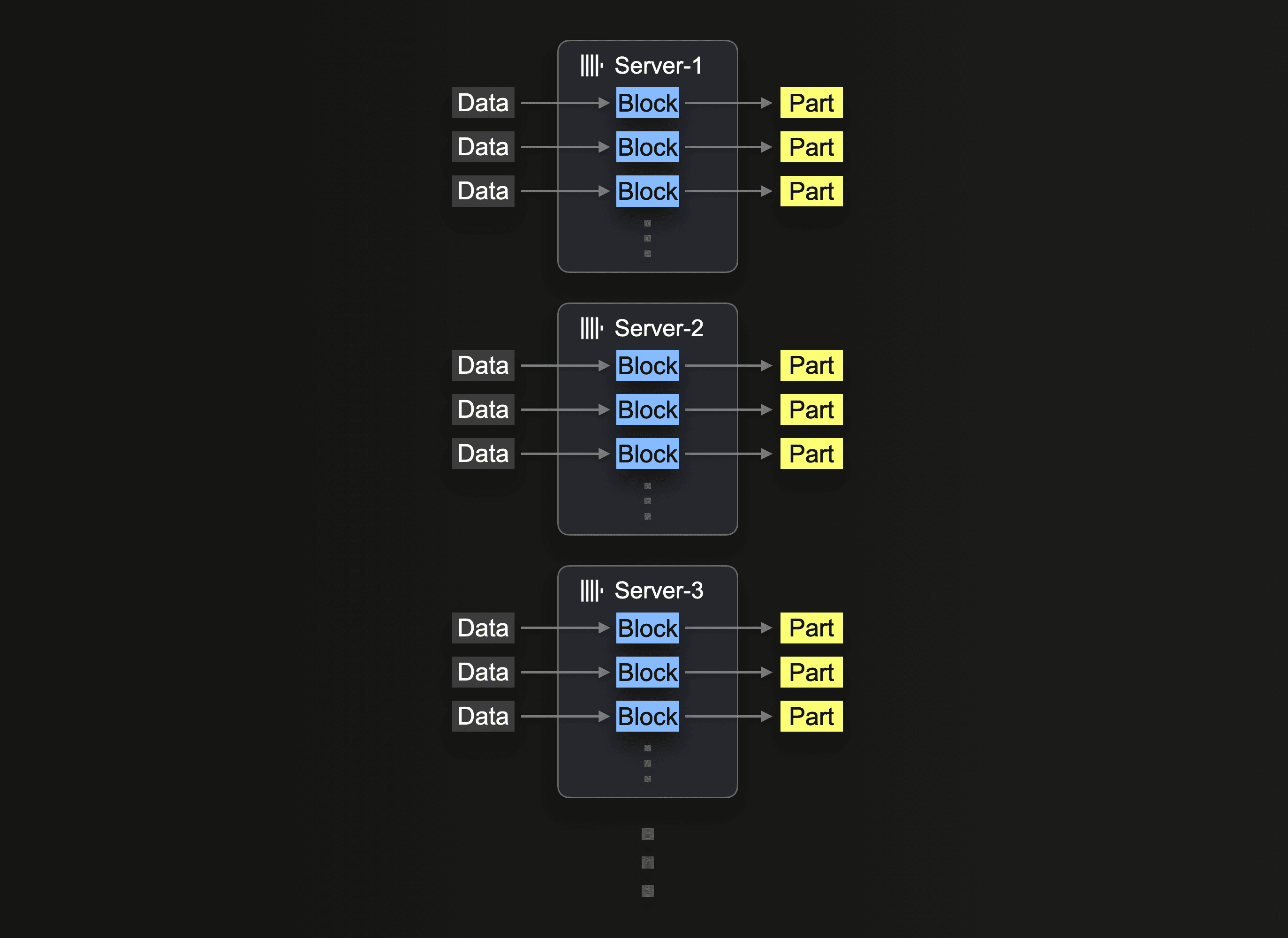
Мы повторяем наш предыдущий запрос чтения, распределяя нагрузку по 3 узлам и изменяя запрос для использования s3Cluster. В ClickHouse Cloud это выполняется автоматически при обращении к кластеру default.
Как отмечено в разделе Utilizing Clusters, эта работа распределяется на уровне отдельных файлов. Чтобы воспользоваться этим механизмом, пользователям потребуется достаточное количество файлов, то есть по крайней мере больше, чем количество узлов.
Аналогично, наш запрос на вставку может быть распределён с использованием улучшенных настроек, определённых ранее для одного узла:
Читатели заметят, что чтение файлов улучшило производительность запросов на чтение, но не операций вставки. По умолчанию, хотя чтение и распределяется с использованием s3Cluster, вставки выполняются на инициирующем узле. Это означает, что чтение будет происходить на каждом узле, но полученные строки будут маршрутизироваться к инициатору для распределения. В сценариях с высокой пропускной способностью это может стать узким местом. Чтобы устранить это, установите параметр parallel_distributed_insert_select для функции s3cluster.
Установка значения parallel_distributed_insert_select=2 гарантирует, что SELECT и INSERT будут выполняться на каждом сегменте к/из основной таблицы движка Distributed на каждом узле.
Как и ожидалось, это снижает производительность операций вставки в 3 раза.
Дополнительная настройка
Отключение дедупликации
Операции вставки иногда могут завершаться с ошибкой, например из‑за тайм‑аута. В таких случаях данные могли быть как успешно вставлены, так и нет. Чтобы клиент мог безопасно повторять неудачные вставки, по умолчанию в распределённых развертываниях, таких как ClickHouse Cloud, ClickHouse пытается определить, были ли данные уже успешно вставлены. Если вставленные данные помечены как дубликат, ClickHouse не вставляет их в целевую таблицу. Однако пользователь всё равно получит статус успешного выполнения операции, как если бы данные были вставлены обычным образом.
Такое поведение, которое приводит к дополнительным накладным расходам при вставке, оправдано при загрузке данных с клиента или при пакетной загрузке, но может быть излишним при выполнении INSERT INTO SELECT из объектного хранилища. Отключив эту функциональность на этапе выполнения вставки, мы можем улучшить производительность, как показано ниже:
Оптимизация при вставке
В ClickHouse настройка optimize_on_insert определяет, будут ли части данных сливаться во время операции вставки. Когда она включена (optimize_on_insert = 1 по умолчанию), небольшие части объединяются в более крупные по мере вставки, что улучшает производительность запросов за счёт уменьшения количества частей, которые нужно прочитать. Однако такое слияние добавляет накладные расходы к процессу вставки и может замедлить вставку с высокой пропускной способностью.
Отключение этой настройки (optimize_on_insert = 0) пропускает слияние во время вставки, позволяя записывать данные быстрее, особенно при частых небольших вставках. Процесс слияния переносится в фоновый режим, что повышает производительность вставки, но временно увеличивает количество маленьких частей, что может замедлить выполнение запросов до завершения фонового слияния. Эта настройка оптимальна, когда приоритетом является производительность вставки, а фоновый процесс слияния может эффективно выполнить оптимизацию позже. Как показано ниже, отключение этой настройки может повысить пропускную способность вставки:
Прочие заметки
- При ограниченном объёме памяти рассмотрите возможность уменьшить значение
max_insert_delayed_streams_for_parallel_writeпри вставке данных в S3.
