Миграция данных
Это часть 1 руководства по миграции с PostgreSQL на ClickHouse. На практическом примере показано, как эффективно выполнить миграцию с использованием подхода репликации данных в режиме реального времени (CDC — фиксация изменений данных). Многие описанные концепции также применимы к ручной массовой передаче данных из PostgreSQL в ClickHouse.
Набор данных
В качестве примерного набора данных, демонстрирующего типичную миграцию из Postgres в ClickHouse, мы используем набор данных Stack Overflow, описанный здесь. Он содержит каждую запись типов post, vote, user, comment и badge, появившуюся на Stack Overflow с 2008 по апрель 2024 года. Схема PostgreSQL для этих данных показана ниже:
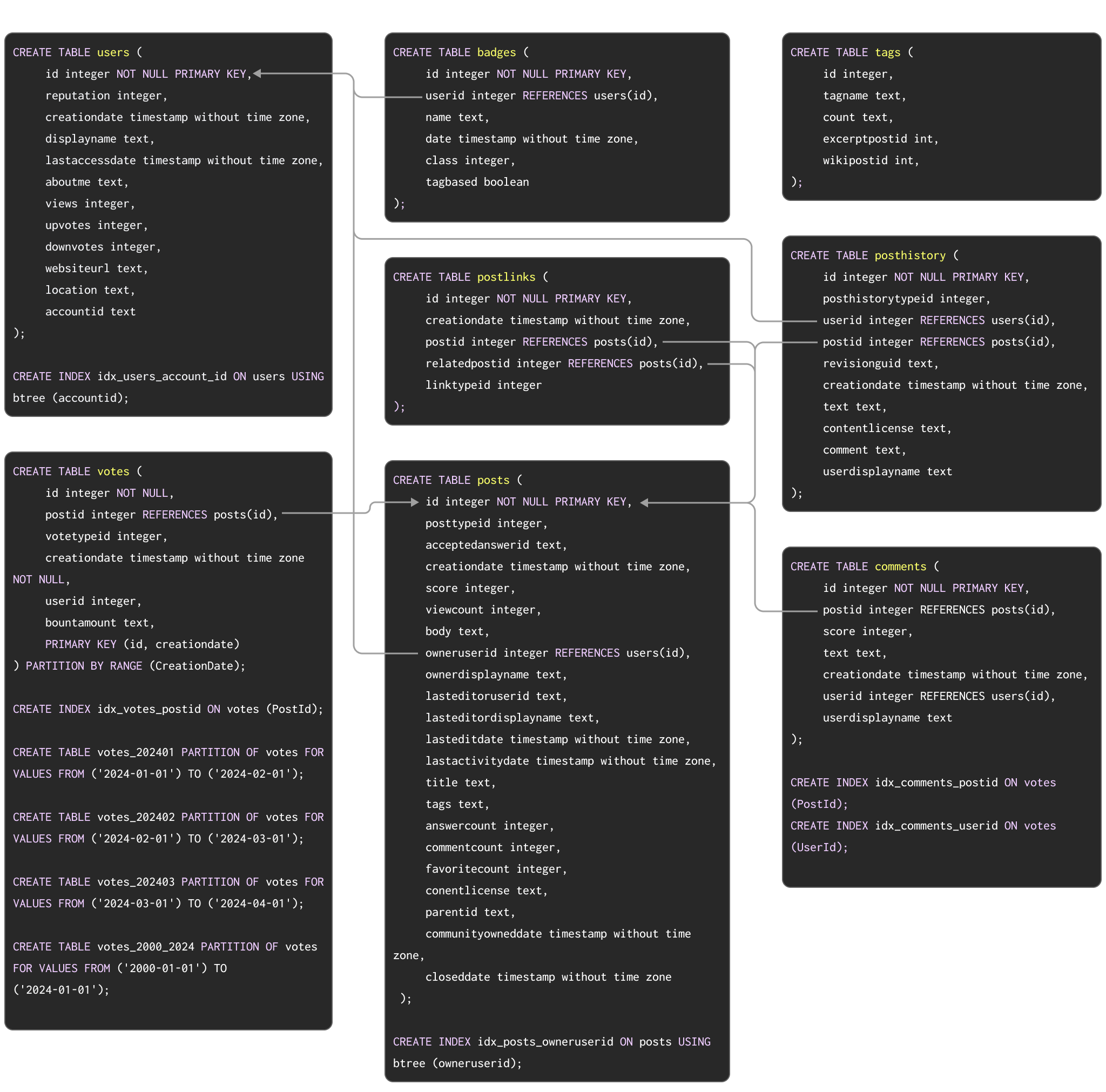
Команды DDL для создания таблиц в PostgreSQL доступны здесь.
Эта схема, хотя и не обязательно оптимальная, использует ряд популярных возможностей PostgreSQL, включая первичные ключи, внешние ключи, партиционирование и индексы.
Мы отобразим каждую из этих концепций на их эквиваленты в ClickHouse.
Для пользователей, которые хотят загрузить этот набор данных в экземпляр PostgreSQL для тестирования шагов миграции, мы предоставили данные в формате pg_dump для скачивания вместе с DDL, а последующие команды загрузки данных приведены ниже:
Хотя для ClickHouse этот набор данных небольшой, для Postgres он является значительным. Приведённый выше фрагмент охватывает первые три месяца 2024 года.
Хотя в наших примерах результатов используется полный набор данных, чтобы показать различия в производительности между Postgres и Clickhouse, все описанные ниже шаги функционально идентичны и для меньшего поднабора данных. Пользователи, желающие загрузить полный набор данных в Postgres, могут ознакомиться с инструкциями здесь. Из‑за внешних ограничений, накладываемых приведённой выше схемой, полный набор данных для PostgreSQL содержит только строки, удовлетворяющие требованиям ссылочной целостности. Версию в формате Parquet без таких ограничений при необходимости можно легко загрузить напрямую в ClickHouse.
Миграция данных
Репликация в режиме реального времени (CDC)
Обратитесь к этому руководству, чтобы настроить ClickPipes для PostgreSQL. В нём рассматриваются многие типы исходных экземпляров Postgres.
При использовании подхода CDC (фиксация изменений данных) с ClickPipes или PeerDB каждая таблица в базе данных PostgreSQL автоматически реплицируется в ClickHouse.
Чтобы обрабатывать обновления и удаления в режиме, близком к реальному времени, ClickPipes сопоставляет таблицы Postgres с таблицами в ClickHouse, используя движок ReplacingMergeTree, специально разработанный для обработки обновлений и удалений в ClickHouse. Дополнительную информацию о том, как данные реплицируются в ClickHouse с помощью ClickPipes, можно найти здесь. Важно отметить, что репликация с использованием CDC создаёт дублирующиеся строки в ClickHouse при репликации операций обновления и удаления. См. способы использования модификатора FINAL для их обработки в ClickHouse.
Рассмотрим, как создаётся таблица users в ClickHouse с использованием ClickPipes.
После настройки ClickPipes начинает миграцию всех данных из PostgreSQL в ClickHouse. В зависимости от сети и масштаба развертываний для набора данных Stack Overflow это должно занять всего несколько минут.
Ручная массовая загрузка с периодическими обновлениями
При использовании ручного подхода первоначальная массовая загрузка набора данных может быть выполнена с помощью:
- Табличные функции — использование табличной функции Postgres в ClickHouse для выполнения
SELECTданных из Postgres и ихINSERTв таблицу ClickHouse. Актуально для массовых загрузок для наборов данных объёмом до нескольких сотен ГБ. - Экспорт — экспорт в промежуточные форматы, такие как CSV или файл с SQL‑скриптом. Эти файлы затем могут быть загружены в ClickHouse либо с клиента с помощью конструкции
INSERT FROM INFILE, либо с использованием объектного хранилища и соответствующих функций, т.е. S3, GCS.
При ручной загрузке данных из PostgreSQL необходимо сначала создать таблицы в ClickHouse. Обратитесь к этой документации по моделированию данных, в которой также используется набор данных Stack Overflow для оптимизации схемы таблиц в ClickHouse.
Типы данных в PostgreSQL и ClickHouse могут отличаться. Чтобы установить эквивалентные типы данных для каждого столбца таблицы, можно использовать команду DESCRIBE с табличной функцией Postgres. Следующая команда описывает таблицу posts в PostgreSQL, модифицируйте её в соответствии с вашей средой:
Общий обзор сопоставления типов данных между PostgreSQL и ClickHouse приведён в документации в приложении.
Шаги по оптимизации типов для этой схемы идентичны шагам для случая, когда данные были загружены из других источников, например из Parquet в S3. Применение процесса, описанного в этом альтернативном руководстве по использованию Parquet, приводит к следующей схеме:
Мы можем заполнить её с помощью простого INSERT INTO SELECT, прочитав данные из PostgreSQL и записав их в ClickHouse:
Инкрементальные загрузки, в свою очередь, можно выполнять по расписанию. Если таблица Postgres только принимает вставки и в ней есть монотонно увеличивающийся идентификатор или метка времени, можно использовать описанный выше подход с табличной функцией для загрузки инкрементов, т.е. к SELECT можно применить предложение WHERE. Этот подход также может использоваться для поддержки обновлений, если гарантируется, что при обновлениях изменяется один и тот же столбец. Поддержка удалений, однако, потребует полной перезагрузки, что может быть трудно осуществить по мере роста таблицы.
Мы демонстрируем начальную загрузку и инкрементальную загрузку, используя CreationDate (предполагаем, что это поле обновляется при обновлении строк).
ClickHouse будет передавать простые условия
WHERE, такие как=,!=,>,>=,<,<=иIN, на сервер PostgreSQL. Инкрементальные загрузки таким образом могут быть сделаны более эффективными, если убедиться, что по столбцам, используемым для идентификации набора изменений, существует индекс.
Один из возможных способов обнаружения операций UPDATE при использовании репликации запросов — использовать системный столбец
XMIN(ID транзакций) в качестве водяного знака: изменение в этом столбце указывает на изменение и, следовательно, может быть применено к целевой таблице. Пользователям, применяющим этот подход, следует учитывать, что значенияXMINмогут циклически повторяться (wrap around), а сравнения требуют полного сканирования таблицы, что усложняет отслеживание изменений.
